Jeżeli interesują Cię szczegółowe statystyki tekstu przeanalizowanego przez Jasnopis albo chcesz poznać stopień trudności tego tekstu obliczony za pomocą innych wzorów, to kliknij przycisk Statystyki. Po jego kliknięciu wyświetlone zostaną informacje liczbowe odnoszące się do różnych językowych cech tekstu. Informacje te mają różny charakter i dlatego zostały podane w postaci kilku bloków.
Wskaźnik mglistości, czyli Fog Index. Indeks opracowany przez Roberta Gunniga wskazujący, ile lat edukacji potrzebujemy (w oryginalnej wersji – amerykańskiej), żeby zrozumieć dany tekst. Indeks mglistości wyliczany jest wg wzoru T=0,4×(Tw+Ts), gdzie Tw to średnia liczba wyrazów w zdaniu, a Ts to procent wyrazów trudnych (czyli dłuższych niż przeciętne w danym języku). W języku polskim przyjmuje się, że wyraz trudny ma cztery sylaby lub więcej (dla tekstów angielskich – trzy sylaby lub więcej).
Jasnopis oblicza trzy warianty indeksu mglistości:
- FOG: Formy hasłowe: w tym wariancie Jasnopis uznaje za wyrazy trudne te, których formy hasłowe mają cztery sylaby lub więcej (np. jeśli w tekście występuje wyraz „podmiotami”, nie traktujemy go jako trudny, bo jego forma hasłowa ma tylko dwie sylaby: pod-miot).
- FOG: Formy tekstowe: w tym wariancie Jasnopis uznaje za wyrazy trudne te, których formy w tekście mają cztery sylaby lub więcej (w tym wariancie „podmiotami” zostanie potraktowana jako wyraz trudny).
- FOG: Rzadkie hasłowe: w tym wariancie Jasnopis uznaje za wyrazy trudne te, których formy hasłowe mają cztery sylaby lub więcej (jak w pierwszym wariancie), z wyjątkiem wyrazów powszechnie znanych. Wyrazy powszechnie znane to wyrazy należące do 5 tys. wyrazów najczęściej występujących w polskich tekstach lub wyrazy o dużym tzw. prawdopodobieństwie subiektywnym – por. J. Imiołczyk (1987).
Indeks Pisarka, czyli współczynniki trudności tekstu wg liniowego (L w nazwie indeksu) wzoru Walerego Pisarka* oraz współczynniki trudności tekstu wg pierwotnego (nieliniowego: NL) wzoru Walerego Pisarka:
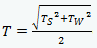
gdzie
Tw to średnia liczba wyrazów w zdaniu, a
Ts to procent wyrazów czterosylabowych lub dłuższych.
Każdy z tych współczynników obliczany jest w trzech wariantach analogicznych do wariantów indeksu mglistości:
- L-Pisarek: Formy hasłowe,
- L-Pisarek: Formy tekstowe,
- L-Pisarek: Rzadkie hasłowe,
- NL-Pisarek: Formy hasłowe,
- NL-Pisarek: Formy tekstowe,
- NL-Pisarek: Rzadkie hasłowe.
Tekst w liczbach podaje podstawowe dane statystyczne analizowanego tekstu:
- Liczba akapitów – może być w pewnym sensie zawyżona, jeżeli tekst zawiera listy (punktowane lub numerowane). Akapitem jest dla Jasnopisu każdy fragment tekstu pomiędzy znakami akapitu/końca linii (w MS Word jest to znak ¶).
- Liczba zdań – jest wyliczana na podstawie znaków interpunkcyjnych oraz znaków końca akapitu. Znaki interpunkcyjne oznaczające koniec zdania to kropka (z wyjątkiem kropki po skrótach lub liczbach), pytajnik oraz wykrzyknik**. Każdy fragment tekstu rozpoczynający się od nowego akapitu lub po znaku interpunkcyjnym oznaczającym koniec zdania i kończący się znakiem końca akapitu jest traktowany jako zdanie.
- Liczba słów – dla Jasnopisu słowem jest każdy ciąg liter lub cyfr nierozdzielony spacją (odstępem) lub znakiem interpunkcyjnym (w tym łącznikiem)**. Na przykład w zdaniu: „To jest 4. wydanie słownika angielsko-polskiego.” Jasnopis wykryje 7 słów, a we frazie „pokój 4-osobowy” – trzy słowa. Symbole lub ciągi symboli typu: +, #, %, (+) nie są traktowane jako słowa.
- Liczba słów trudnych – dla Jasnopisu słowa trudne to takie, których formy hasłowe mają cztery sylaby lub więcej i które nie są powszechnie znane, tzn. nie są to wyrazy należące do 5 tys. wyrazów najczęściej występujących w polskich tekstach ani nie są to wyrazy o dużym tzw. prawdopodobieństwie subiektywnym – por. J. Imiołczyk (1987).
Średnie długości jednostek tekstu – tutaj podajemy informacje o średniej długości słowa (wyrazu tekstowego), średniej długości zdania i średniej długości akapitu:
- Średnia długość słowa – wynik dzielenia liczby wszystkich sylab, z których składa się tekst, przez liczbę wszystkich słów w tekście. Im średnia długość słowa jest większa, tym tekst jest trudniejszy w odbiorze.
- Średnia długość zdania – wynik dzielenia liczby wszystkich słów w tekście przez liczbę zdań.
- Średnia długość akapitu – wynik dzielenia liczby wszystkich słów w tekście przez liczbę akapitów.
Tekst w procentach:
- Procent słów trudnych – iloraz liczby słów uznanych za trudne do całkowitej liczby słów w tekście razy 100%.
- Procent rzeczowników – iloraz liczby wykrytych w tekście form rzeczowników do liczby wszystkich słów razy 100%. Jako rzeczowniki traktowane są też tzw. gerundia, czyli rzeczowniki odczasownikowe typu czytanie, plucie, rzeczownikowe nazwy cech typu niewinność, przezroczystość oraz wyrazy typu chory w wyraźnej funkcji rzeczownikowej (np. „W sali leżało dwóch chorych”).
- Procent rzeczowników trudnych – iloraz wykrytych w tekście wystąpień rzeczowników trudnych do liczby wystąpień wszystkich słów razy 100%.
- Procent czasowników – iloraz liczby wykrytych w tekście form czasowników do liczby wszystkich słów razy 100%. Jako formy czasowników nie są traktowane imiesłowy przymiotnikowe i przysłówkowe.
- Procent czasowników trudnych – obliczany jest analogicznie do procentu rzeczowników trudnych.
- Procent przymiotników – iloraz liczby wykrytych w tekście form przymiotników do liczby wszystkich słów razy 100%.
- Procent przymiotników trudnych – obliczany jest analogicznie do procentu rzeczowników trudnych.
Inne, czyli pozostałe parametry wpływające na trudność tekstu:
- Stosunek rzeczowników do czasowników – iloraz wszystkich znalezionych w tekście rzeczowników do wszystkich znalezionych w tekście czasowników.
- Stosunek przymiotników do czasowników – iloraz wszystkich znalezionych w tekście przymiotników do wszystkich znalezionych w tekście czasowników.
- Stosunek przymiotników do rzeczowników – iloraz wszystkich znalezionych w tekście przymiotników do wszystkich znalezionych w tekście rzeczowników.
- Procent słów z prefiksem „nie” – iloraz liczby słów z prefiksem „nie” do całkowitej liczby słów razy 100%.
- Procent imiesłowów – iloraz liczby imiesłowów do całkowitej liczby słów razy 100%.
- Procent gerundiów – iloraz liczby gerundiów do całkowitej liczby słów razy 100%.
- Procent rzeczowników kończących się na „ość” – iloraz liczby rzeczowników kończących się na „ość” do całkowitej liczby słów razy 100%.
- Procent czasowników w formie bezosobowej – iloraz liczby czasowników w formie bezosobowej do całkowitej liczby słów razy 100%.
- Procent rzeczowników w dopełniaczu – iloraz liczby rzeczowników w dopełniaczu do całkowitej liczby słów razy 100%.
- Średnia długość łańcuchów dopełniaczowych – średnia długość ciągów rzeczowników (wyrażona w słowach), z których każdy kolejny odpowiada na pytanie kogo, czego, np. „w przypadku braku możliwości uruchomienia pojazdu”.
- Procent słów długich – iloraz liczby słów długich (4 lub więcej sylab) do całkowitej liczby słów w tekście razy 100%.
- Procent słów długich (mniej znanych) – iloraz liczby słów długich (4 lub więcej sylab) o niskim prawdopodobieństwie subiektywnym do całkowitej liczby słów w tekście razy 100%.
* Wzór liniowy zrekonstruowany został na podstawie podziałki zawartej w publikacjach W. Pisarka.
** W praktyce do podziału tekstu na zdania i słowa wykorzystywane jest narzędzie informatyczne nazywane tagerem. Reguły jego działania są znacznie bardziej skomplikowane niż te tutaj przedstawione.


